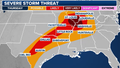
'IT MUST BE JELLY'
ENTERTAINMENT



'A KIND OF SALVATION'
ENTERTAINMENT

OUT OF THIS WORLD
LIFESTYLE

MORNING GLORY
OPINION